ocular-disease-intelligent-recognition-deep-learning
ODIR-2019: Ocular Disease Intelligent Recognition is a project leveraging state-of-the-art deep learning architectures to analyze and classify ocular diseases based on medical imaging data. This repository implements advanced machine learning techniques and modern neural network architectures to push the boundaries of intelligent recognition
View the Project on GitHub JordiCorbilla/ocular-disease-intelligent-recognition-deep-learning
Ocular Disease Intelligent Recognition Through Deep Learning Architectures
Welcome to the repository for Jordi Corbilla’s MSc dissertation, titled “Ocular Disease Intelligent Recognition Through Deep Learning Architectures.” The dissertation was published by Universitat Oberta de Catalunya in 2020 and can be accessed through this link: [http://openaccess.uoc.edu/webapps/o2/handle/10609/113126].
The PDFs and sources for the dissertation are licensed under the Creative Commons Attribution license, which is detailed in the LICENSE file. We hope you find the dissertation and associated materials helpful in your own research and learning endeavors.
Abstract
Retinal pathologies are the most common cause of childhood blindness worldwide. Rapid and automatic detection of diseases is critical and urgent in reducing the ophthalmologist's workload. Ophthalmologists diagnose diseases based on pattern recognition through direct or indirect visualization of the eye and its surrounding structures. Dependence on the fundus of the eye and its analysis make the field of ophthalmology perfectly suited to benefit from deep learning algorithms. Each disease has different stages of severity that can be deduced by verifying the existence of specific lesions and each lesion is characterized by certain morphological features where several lesions of different pathologies have similar characteristics. We note that patients may be simultaneously affected by various pathologies, and consequently, the detection of eye diseases has a multi-label classification with a complex resolution principle.
Two deep learning solutions are being studied for the automatic detection of multiple eye diseases. The solutions chosen are due to their higher performance and final score in the ILSVRC challenge: GoogLeNet and VGGNet. First, we study the different characteristics of lesions and define the fundamental steps of data processing. We then identify the software and hardware needed to execute deep learning solutions. Finally, we investigate the principles of experimentation involved in evaluating the various methods, the public database used for the training and validation phases, and report the final detection accuracy with other important metrics.
Keywords
Image classification, Deep learning, Retinography, Convolutional neural networks, Eye diseases, Medical imaging analysis.
Pathologies
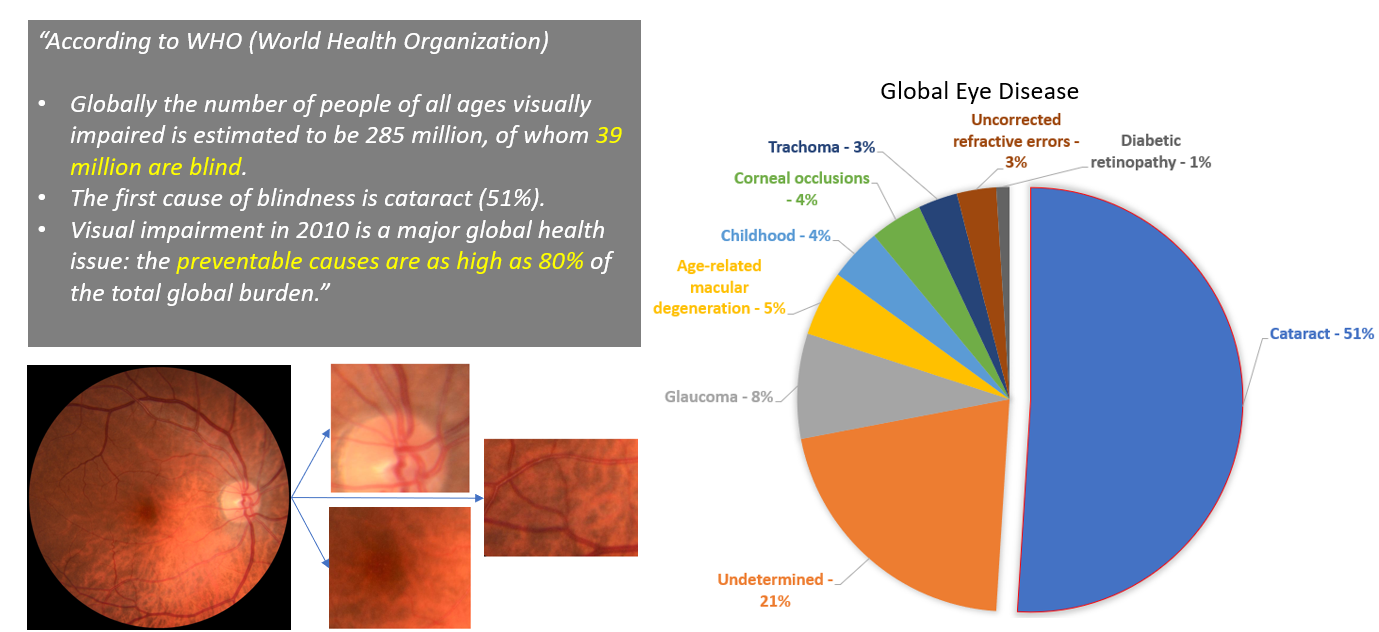
According to 2010 World Health Organization data: The prevalence of preventable blindness is staggering, with over 39 million people affected globally, 80% of whom could have been prevented. In developing countries, cataracts remain the leading cause of blindness, accounting for 51% of cases worldwide.
Currently, the standard method for classifying diseases based on fundus photography involves manual estimation of injury locations and analysis of their severity, which is time-consuming and costly for ophthalmologists and healthcare systems. Therefore, there is a pressing need for automated methods to streamline this process.
Rapid and accurate disease detection is crucial for reducing the workload of ophthalmologists and ensuring timely treatment for patients.
Deep learning architecture
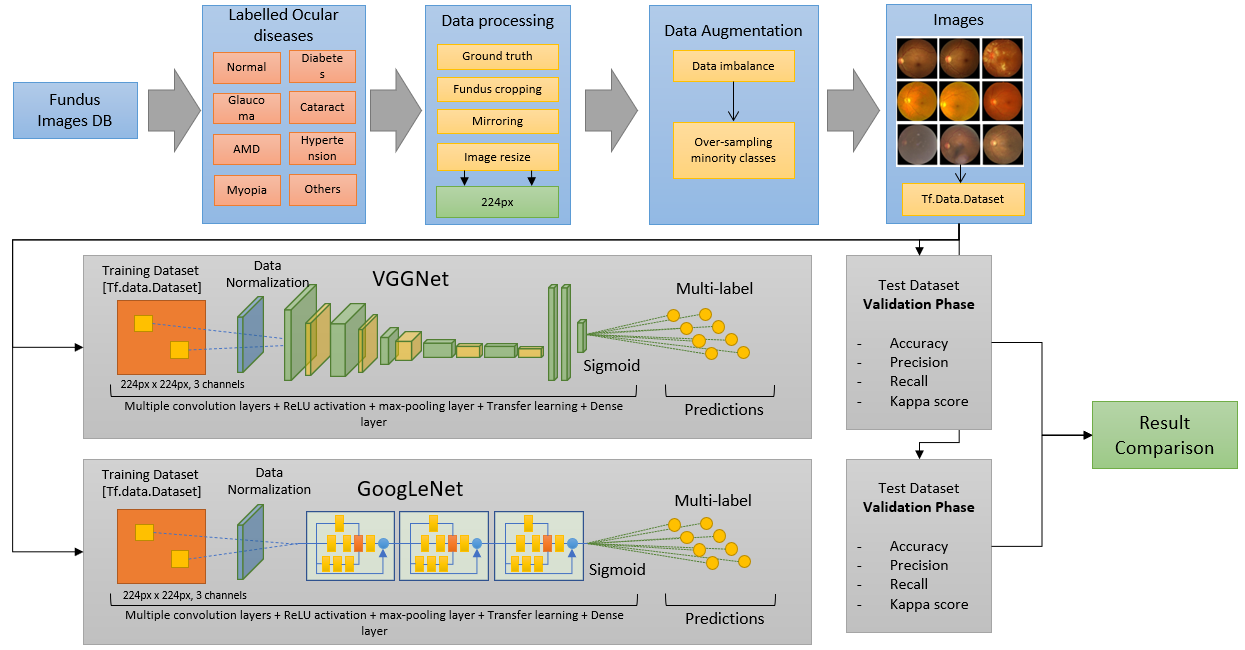
What is our methodology?
Our methodology consists of several steps that enable us to accurately classify medical images into different pathologies. First, we carefully analyze the dataset to ensure that each pathology is correctly represented. Next, we develop algorithms for processing the images, which are then fed into deep learning networks capable of handling them. To address imbalances in the data, we include a data augmentation module that adds variability to the images.
Using these data vectors, we train multiple deep learning models through a series of experiments, each aimed at improving classification accuracy. We adjust the size of the images and conversion blocks to optimize performance, while convolutional layers extract relevant image features and reduce dimensionality. The final decision-making step is handled by a Sigmoid layer.
In the end, we generate and compare results from each experiment to determine the best-performing model. To illustrate our methodology, we have created a flowchart that details each stage of the process.
Training Details
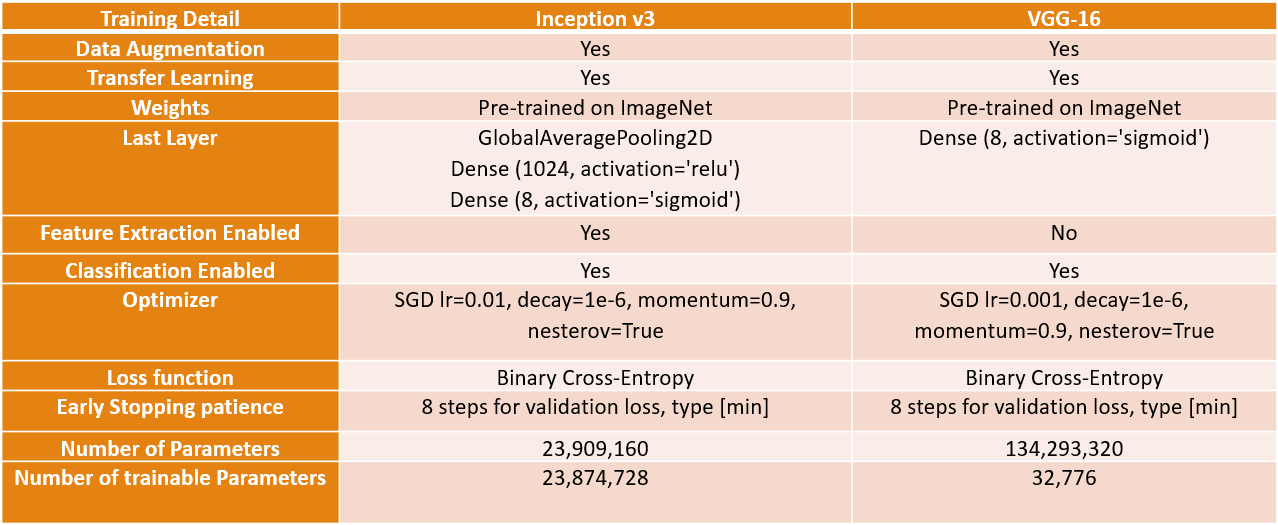
After conducting numerous experiments on the introduced models, we have identified the most effective configurations for each model.
For the Inception model, we utilized data augmentation and initialized the model with ImageNet weights for transfer learning. We enabled both feature extraction and sorting components, as this configuration produced satisfactory results. As previously mentioned, we added a dense layer with a Sigmoid activation to the last layer to compute the loss for each of the 8 classes in the output. We employed Stochastic Gradient Descent with a learning rate of 0.01 and utilized binary cross-entropy as the loss function for the multi-tag configuration. Additionally, we incorporated a patience feature that terminates training if the validation loss fails to decrease for 8 iterations. The model has 23 million trainable parameters.
In the VGG model, we found that transfer learning outperformed training the model from scratch. We loaded the ImageNet weights and modified the last layer to address the multi-label problem, enabling only the classifier component, resulting in 32 thousand trainable parameters. The configuration is similar to the Inception model, except for a reduced learning rate of 0.001.
Model Comparison
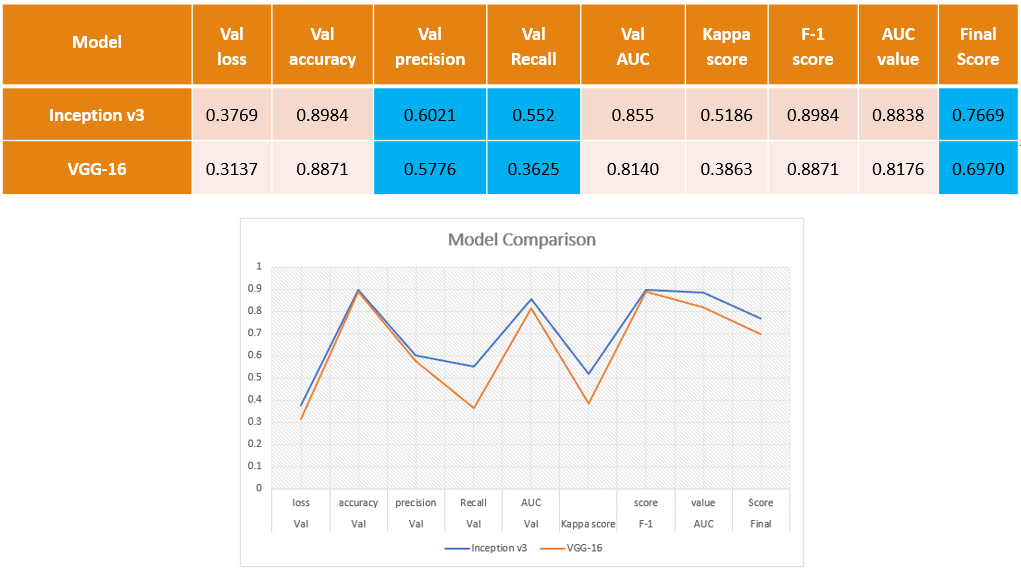
The evaluation of the models reveals that the Inception model outperforms the VGG model, achieving an accuracy of 60% and a recall of 55%. The final score, taking into account the mean value of the Kappa coefficient of Cohen, F1-Score, and AUC, is 76%.
While the VGG model's performance is still impressive, with an accuracy of 57%, its recall is lower at 36%. This means that only 36% of the model's predictions are correct compared to the total number of images that are actually positive. For a more detailed analysis, we have provided a confusion matrix below.
Confusion matrix
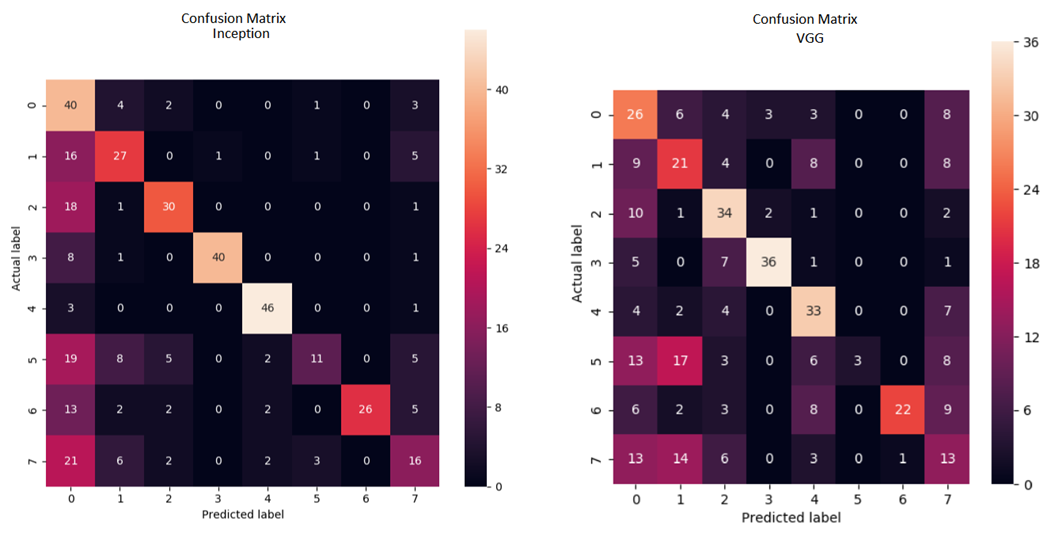
The confusion matrices reveal interesting insights about the performance of the models. The Inception model outperforms the VGG model in correctly classifying images, as indicated by a higher number of values on the diagonal. However, there are still some classes, such as hypertension, where both models struggle to correctly classify images. The Inception model achieves an overall accuracy of 80%, with the exception of hypertension and other pathologies, where its performance drops to 22% and 32% respectively. This indicates that despite using data augmentation, there are still features that the model has not learned. On the other hand, the VGG model achieves an accuracy of 57%, with similar issues in correctly classifying hypertension images. Overall, both models show promise in recognizing ocular diseases, but further improvements are needed to address the misclassifications in certain classes.
Classification Output
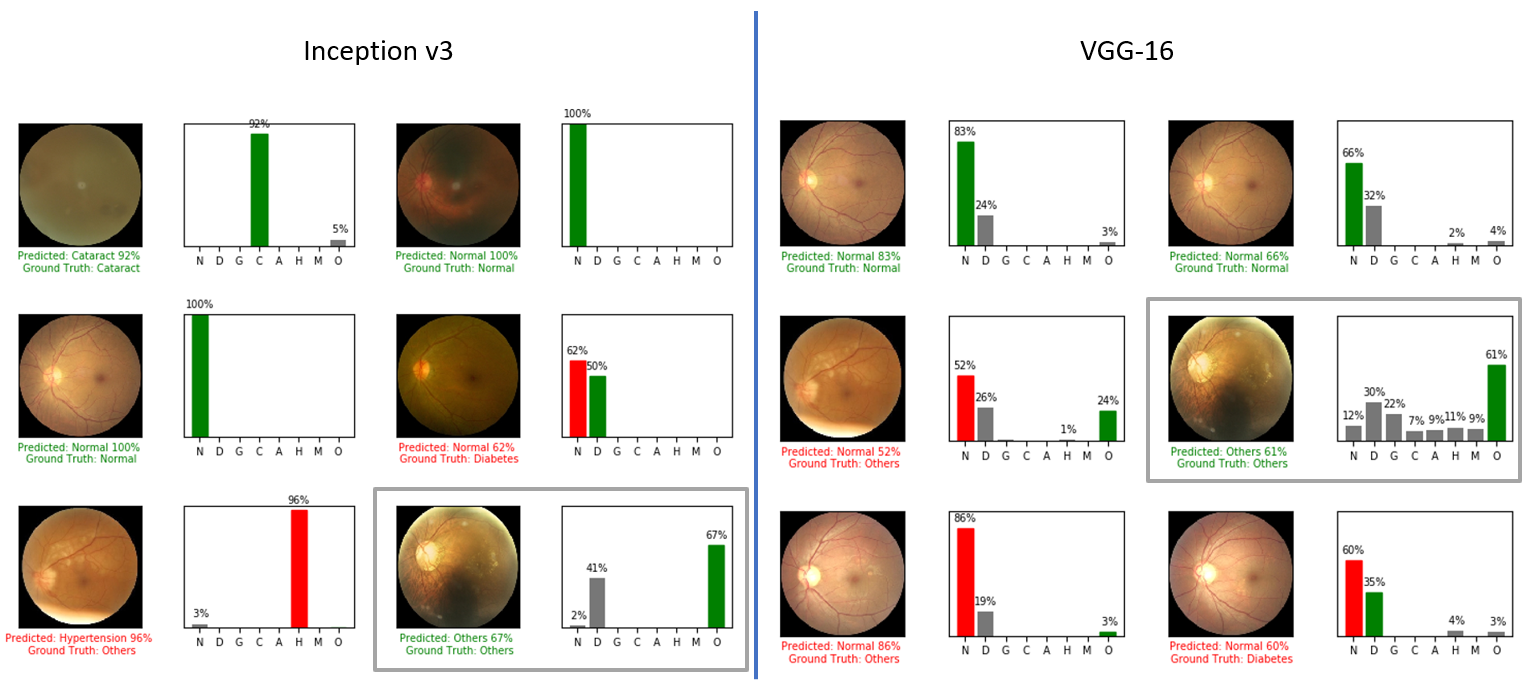
The final section of the report presents the output of each model and provides some conclusions. The code for training, validation, and inference is included in this repository, allowing for reproducibility and further exploration.
Upon examining the model output, we can see that both models produce the same classification for each image. However, upon closer inspection, we can see that the response of each model's output differs significantly.
Conclusions
In conclusion, this project explores the use of two deep learning models for the classification of ocular diseases, addressing the challenges posed by multi-label classification and data imbalance. The experiments have shown that the models can achieve an accuracy of 60% on the validation set after fine-tuning. The results suggest that these models could be applied in practice to assist ophthalmologists in classifying fundus images more efficiently.
Implementation Details
Dataset
The Dataset is part of the ODIR 2019 Grand Challenge. In order to use the data you need to register and download it from there: https://odir2019.grand-challenge.org/introduction/
Works on Python 3.6
tensorflow-2.0 - use branch master
The full list of packages used can be seen below:
- tensorboard-2.0.0
- tensorflow-2.0.0
- tensorflow-estimator-2.0.1
- tensorflow-gpu-2.0
- matplotlib-3.1.1
- keras-applications-1.0.8
- keras-preprocessing-1.0.5
- opencv-python-4.1.1.26
- django-2.2.6
- image-1.5.27
- pillow-6.2.0
- sqlparse-0.3.0
- IPython-7.8.0
- keras-2.3.1
- scikit-learn-0.21.3
- pydot-1.4.1
- graphviz-0.13.2
- pylint-2.4.4
- imbalanced-learn-0.5.0
- seaborn-0.9.0
- scikit-image-0.16.2
- pandas-0.25.1
- numpy 1.17.2
- scipy-1.3.1
All the training images must be in JPEG format and with 224x224px.
Usage
1) Image Treatment Process
Place all the files in the following folders (Training and Validation images):
c:\temp\ODIR-5K_Training_Dataset
c:\temp\ODIR-5K_Testing_Images
The training images Dataset should contain 7000 images and the testing Dataset 1000 images. Below is a screenshot of the images in the training dataset folder:
Then, create the following folders:
c:\temp\ODIR-5K_Testing_Images_cropped
c:\temp\ODIR-5K_Testing_Images_treated_128
c:\temp\ODIR-5K_Testing_Images_treated_224
c:\temp\ODIR-5K_Training_Dataset_cropped
c:\temp\ODIR-5K_Training_Dataset_treated_128
c:\temp\ODIR-5K_Training_Dataset_treated_224
c:\temp\ODIR-5K_Training_Dataset_augmented_128
c:\temp\ODIR-5K_Training_Dataset_augmented_224
run the following command to treat the training and validation images:
//These two remove the black pixels
python odir_image_crop_job.py
python odir_image_testing_crop_job.py
//These two resize the images to 224 pixels
python odir_training_image_treatment_job.py
python odir_testing_image_treatment_job.py
The odir_image_crop_job.py job will treat all the Training Dataset images and remove the black area of the images so the images end up like in the image below (same job for the odir_image_testing_crop_job.py which will act upon the training images):
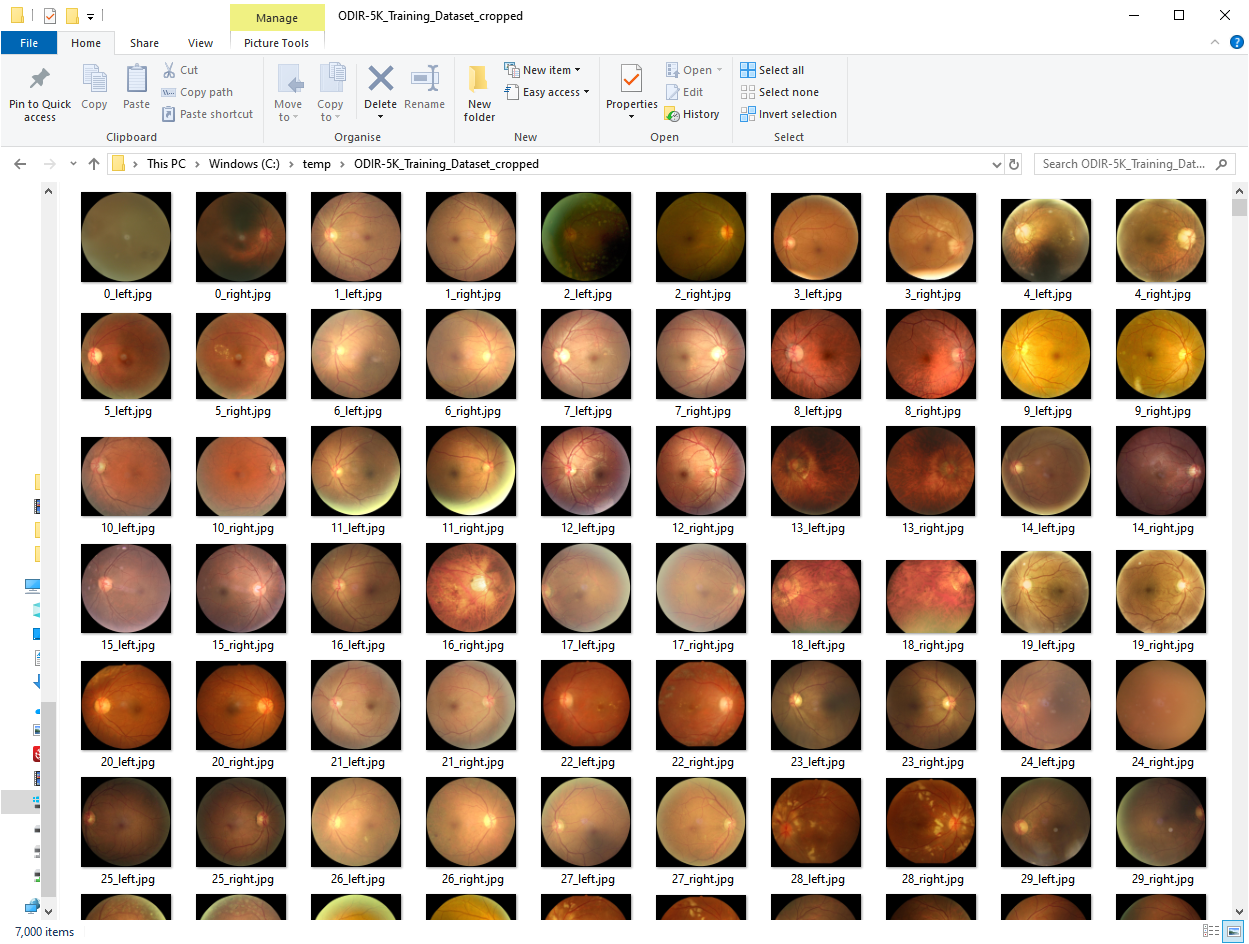
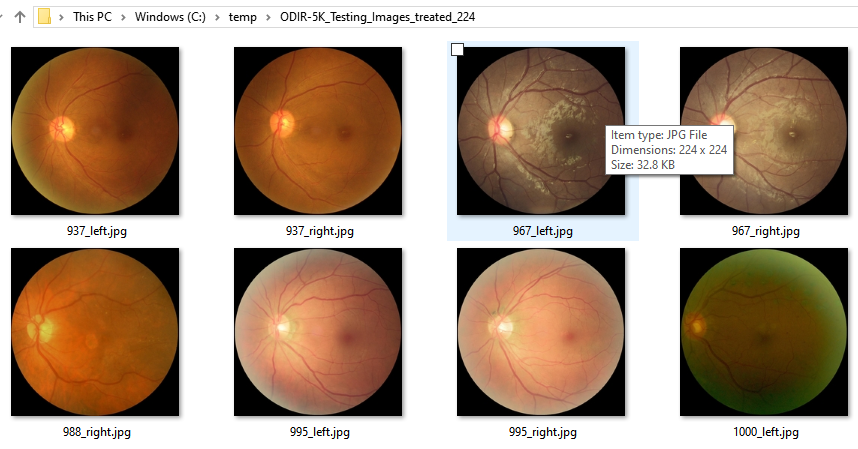
The second job will perform the resize and squaring functionality to 224 pixels x 224 pixels. The parameters image_width and keep_aspect_ratio variables can be edited in the python file to test different values/scenarios. This should give you images like the ones below:
2) Data Augmentation (if you don’t want to use this step you can skip it)
run the following command to generate the additional images:
python.exe odir_data_augmentation_runner.py
This will generate the odir_augmented.csv file.
3) Image to tf.Data conversion and .npy storage
Now that we have all the images. We need to translate them into a td.Data component so we can load them into our model. Run the following command to generate the dataset for training and validation:
python.exe odir_patients_to_numpy.py
Note that any changes in the images will need a re-run of this script to rebuild the .npy files.
If you take a look at the arguments of the script you will see the following:
image_width = 224
training_path = r'C:\temp\ODIR-5K_Training_Dataset_treated' + '_' + str(image_width)
testing_path = r'C:\temp\ODIR-5K_Testing_Images_treated' + '_' + str(image_width)
augmented_path = r'C:\temp\ODIR-5K_Training_Dataset_augmented' + '_' + str(image_width)
csv_file = r'ground_truth\odir.csv'
csv_augmented_file = r'ground_truth\odir_augmented.csv'
training_file = r'ground_truth\testing_default_value.csv'
odir.csv file contains the generated ground truth per eye. To generate the ground truth, you can take a look at odir_runner.py which contains the different procedures to generate the ground truth based on the ODIR-5K_Training_Annotations(Updated)_V2.xlsx file which is part of the provided file by ODIR.
odir_augmented.csv contains the generated ground truth per eye and sample of the data augmentation process generator. This makes things easier when trying to feed this into the model and compare the results.
testing_default_value.csv contains the vectors of the testing images.
Deep Learning Models
4) Run Inception-v3
-- Basic Run of the model
python.exe odir_inception_v3_training_basic.py
Sample output can be seen here: readme.md
-- Enhanced Run of the model using Data Augmentation
python.exe odir_inception_training.py
Sample output can be seen here: readme.md
4.1) Inception Inference
python.exe odir_inception_testing_inference.py
5) Run VGG16
-- Basic Run of the model
python.exe odir_vgg16_training_basic.py
-- Enhanced Run of the model using Data Augmentation
python.exe odir_vgg16_training.py
- Sample output can be seen here: readme.md
5.1) VGG16 Inference
python.exe odir_vgg_testing_inference.py
Deep Learning Models (Additional - out of the scope of this dissertation)
6) Run VGG19
-- Basic Run of the model
python.exe odir_vgg19_training_basic.py
-- Enhanced Run of the model using Data Augmentation
python.exe odir_vgg19_training.py
- Sample output can be seen here: readme.md
6.1) VGG19 Inference
python.exe odir_vgg19_testing_inference.py
7) Run ResNet50
-- Basic Run of the model
python.exe odir_resnet50_training_basic.py
- Sample output can be seen here: readme.md
-- Enhanced Run of the model using Data Augmentation
python.exe odir_resnet50_training.py
- Sample output can be seen here: readme.md
7.1) ResNet50 Inference
python.exe odir_resnet50_testing_inference.py
8) Run InceptionResNetV2
-- Basic Run of the model
python.exe odir_inception_ResNetV2_training_basic.py
- Sample output can be seen here: [readme.md]
-- Enhanced Run of the model using Data Augmentation
python.exe odir_inception_ResNetV2_training.py
- Sample output can be seen here: readme.md
8.1) ResNet50 Inference
python.exe odir_inception_ResNetV2_testing_inference.py
References
- Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado, G.S., Davis, A., Dean, J., Devin, M., Ghemawat, S., Goodfellow, I., Harp, A., and, … (2016). Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv preprint arXiv:1603.04467.
- Lee, M. Seattle, P. Taylor, U. Kingdom. Machine learning has arrived! Ophthalmology. (2017), pp. 1726-1728.
- Bengio, Y., Courville, A. and Vincent, P. (2013). Representation Learning: A Review and New Perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8), pp.1798-1828.
- Bonet, E. (2018). Què és un fons d’ull? Servei d’Oftalmologia. Fundació Hospital de nens de Barcelona, p.1.
- Carletta, Jean. (1996) Assessing agreement on classification tasks: The kappa statistic. Computational Linguistics, 22(2), pp. 249–254
- C.I. Sánchez, M. Niemeijer, I. Išgum, A.V. Dumitrescu, M.S.A. Suttorp-Schulten, M.D. Abràmoff and B. van Ginneken. “Contextual computer-aided detection: Improving bright lesion detection in retinal images and coronary calcification identification in CT scans”, Medical Image Analysis 2012;16(1):50-62
- C.I. Sánchez, M. Niemeijer, A.V. Dumitrescu, M.S.A. Suttorp-Schulten, M.D. Abràmoff and B. van Ginneken. “Evaluation of a Computer-Aided Diagnosis system for Diabetic Retinopathy screening on public data”, Investigative Ophthalmology and Visual Science 2011;52:4866-4871.
- Fawcett, Tom (2006) “An Introduction to ROC Analysis”(PDF). Pattern Recognition Letters. 27 (8): 861–874.
- García, B., De Juana, P., Hidalgo, F and Bermejo, T. (2010). Oftalmología. Farmacia hospitalaria Tomo II. Publicado por la SEFH. Capítulo 15.
- Garrido, R. (2011). Epidemiología descriptiva del estado refractiva en estudiantes universitarios. Universidad Complutense de Madrid, p.339.
- Gilbert, C., Foster A. (2001). Childhood blindness in the context of VISION 2020 – the right sight. Bull World Health Organ, 79(3):227-32.
- Hijazi, S., Kumar, R. Rowen, C. Using Convolutional Neural Networks for Image Recognition. 2015. Cadence.
- Jaworek-Korjakowska, J., Kleczek, P., Gorgon, M. Melanoma Thickness Prediction Based on Convolutional Neural Network With VGG-19 Model Transfer Learning. (2019) The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops.
- Kent, Allen; Berry, Madeline M.; Luehrs, Jr., Fred U.; Perry, J.W. (1955). “Machine literature searching VIII. Operational criteria for designing information retrieval systems”. American Documentation. 6 (2): 93. doi:10.1002/asi.5090060209. arXiv preprint arXiv: 1409.4842
- Krizhevsky, A., Sutskever, I. and Hinton, G. (2017). ImageNet classification with deep convolutional neural networks. Communications of the ACM, 60(6), pp.84-90.
- Kusumoto D, Yuasa S. The application of convolutional neural network to stem cell biology. Inflamm Regen. 2019 39:14. Published 2019 Jul 5. doi:10.1186/s41232-019-0103-3.
- Lecun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521(7553):436–444.
- Lyana N. M., & Norshahrizan, N., (2015). The Self-Driving Car.
- M.D. Abramoff, Y. Lou, A. Erginay, et al. Improved automated setection of diabetic retinopathy on a publicly available dataset through integration of deep learning Invest Ophthalmol Vis Sci. (2016), pp. 5200-5206
- Ocular Disease Intelligent Recognition. (2019). ODIR-2019 - Grand Challenge. [online] Available at: https://odir2019.grand-challenge.org/introduction/ [Accessed 27 Sep. 2019].
- Oftalmològica. (2019). Tecnologia per a la revisió de la retina - Àrea Oftalmològica Avançada.
- Parampal S. Grewal, Faraz Oloumi, Uriel Rubin, Matthew T.S. Tennant, Deep learning in ophthalmology: a review, Canadian Journal of Ophthalmology, Volume 53, Issue 4, 2018, Pages 309-313, ISSN 0008-4182,
- Roletschek, R., (2019). [image] Available at: Fahrradtechnik auf fahrradmonteur.de [FAL or GFDL 1.2 license] [Accessed 3 Nov. 2019].
- Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A. and Fei-Fei, L. (2015). ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision, 115(3), pp.211-252.
- Saine, P. and Tyler, M. (2002). Ophthalmic photography. Boston [Mass.]: Butterworth-Heinemann.
- Sermanet, Pierre, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, and Yann LeCun. OverFeat: Integrated Recognition, Localization and Detection Using Convolutional Networks. arXiv:1312.6229 [Cs], December, 2013.
- Simonyan, K. and Zisserman, A. (2015). Very deep convolutional networks for large-scale image recognition. Published as a conference paper at ICLR 2015.
- Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erham, D., Vanhoucke, V., Rabinovich, A. (2014). Going Deeper with Convolutions.
- Ting DSW, Pasquale LR, Peng L, et al Artificial intelligence and deep learning in ophthalmology British Journal of Ophthalmology 2019;103:167-175.
- Tan, N. M., Liu, J., Wong, D. W. K., Lim, J. H., Li, H., Patil, S. B., Yu, W., Wong, T. Y. (2009). Automatic Detection of Left and Right Eye in Retinal Fundus Images. Springer Berlin Heidelberg. pp 610—614.
- Van Rijsbergen, C. J. (1979). Information Retrieval (2nd ed.). Butterworth-Heinemann.
- Xie, S., Girshick, R. and Dollár, P. and Tu, P. and He, K. (2016). Aggregated Residual Transformations for Deep Neural Networks. Cornell University.
- Yorston, D. (2003). Retinal Diseases and VISION 2020. Community Eye Health. 2003;16(46):19–20.
- Zhou, Y., He, X., Huang, L., Liu, L., Zhu, F., Cui, S., Shao, L. (2019). Collaborative Learning of Semi-Supervised Segmentation and Classification for Medical Images. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Links to Materials
- [[vgg_model_summary.md]]
- [[generated_ground_truth.md]]
- [[inception_model_summary.md]]
- [[generated_ground_truth.md]]
- [[list_discarded_images.md]]
- [[odir_training_images_pruning.md]]
- [[configuration.md]]
- [[readme.md]]
License
Creative Commons Attribution-NonCommercial 4.0 International Public License.
Sponsors
No sponsors yet! Will you be the first?
![]()
Support me
![]()